
1. 解释器中字符串的输出
示例代码:
>>> myString = 'Hello world!'>>> myString'Hello world!'>>> print myStringHello world!>>> num = 12>>> num12解释与总结:
1. 使用print函数,则会默认调用str()函数调用对象,而交互解释器则调用repr()函数来显示对象.
2. 如果直接使用变量名,则代表数值本身.则myString输出为单引号(代表字符串),num则为12,代表数值.2. python中print的重定向
示例代码:
>>> with open('test.txt', 'w') as f: print >> f, 'Fatal error: invalid input!'>>> import sys>>> with open('test.txt') as f: print >> sys.stderr, f.read() Fatal error: invalid input! 解释与总结: 1. 使用>>进行重定向输入.
2. 在unix里<<用于重定向输出,但是用>>重定向到输出文件照样可以达到效果.3. 使用raw_input处理用户输入
示例代码:
>>> user = raw_input('Now enter your name:')Now enter your name:leichaojian>>> user'leichaojian'>>> num = raw_input('Now enter a number:')Now enter a number:26>>> num'26'>>> int(num)26 解释与总结: 1. raw_input所输入的数据都是字符串.
2. 如果输入的是数字,要使用int,float等转换为自己需要的数据类型. 3. 一般情况下不推荐在函数内使用raw_input.函数最好保持单一接口,接收参数的输入并处理完后输出.4. 基本数据类型和引用类型在迭代器中的使用
1. 基本数据类型(不可改变):数值,字符串,元组
2. 引用类型: 列表,字典示例代码:
>>> arr = [[1, 2], [3, 4]]>>> [id(x) for x in arr][44646152L, 44664008L]>>> for item in arr: item.append(11) print id(item), 44646152 44664008>>> [id(x) for x in arr][44646152L, 44664008L]解释与总结:
1. 这里会发现,arr中的列表数据的id是不会改变的,即使在增加元素的情况下.
2. 深入的讲解是:arr只是一个指针,或者为一个引用,指向内存中存储[[1, 2], [3, 4]]这个数据.示例代码:
>>> arr = [1, 2]>>> [id(x) for x in arr][29646952L, 29646928L]>>> for item in arr: item = 11 print id(item), 29646712 29646712>>> [id(x) for x in arr][29646952L, 29646928L]
解释与总结:
1. 这里在执行item = 11时,实际上是新建了一个item对象(即此item非for循环里面的item,可以理解为局部对象替换了全局对象),所以它的id变了.
2. 这里引申到函数的设计上:函数的参数最好是元组,这样就可以保证所输入的数据不会被修改.如果是列表,可以使用tuple函数转换为元组.5. python的代码风格
1. 通常为一行一个语句,但是如果一行过长,则使用反斜杠(\)分解.
>>> if 1 and \ 2: print "Hello world!" Hello world!2. 有两种例外情况下,不需要使用反斜杠.一是单一语句可以跨多行(小括号,中括号,花括号),另外是三引号包括的字符.
>>> arr = [1, 2, 3, 4]>>> arr[1, 2, 3, 4]
3. python的代码组由不同的缩进分割,这样的好处如下:
1) 可读性强
2) 避免"悬挂else"问题的产生.
3) 未写大括号所造成的一切问题
4. 注释要确保注释的准确性(不能缺少注释,也不能过度注释,尽可能使注释简洁明了,并放在最合适的地方)
5. 文档
编写类,函数时候注意文档的编写,并使用__doc__来访问.
>>> def func(): """this is a func""" pass>>> func.__doc__'this is a func'6. 模块结构和布局
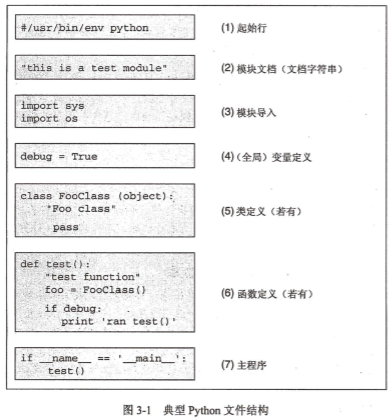
下面就是一个非常合理的布局:
# (1) 起始行(Unix)
# (2) 模块文档
# (3) 模块导入
# (4) 变量定义
# (5) 类定义
# (6) 函数定义
# (7) 主程序
典型Python文件结构如下:
备注: 关于__name__的解释
由于主程序代码无论模块是被导入还是被直接执行都会运行.那么问题出现了:程序在运行时候如何确定模块是被导入还是被直接执行?__name__可以解决这个问题.
1. 如果模块是被导入,__name__的值为模块名字
2. 如果模块是被直接执行,__name__的值为'__main__'
test.py:
print __name__解释器显示如下:
>>> __main__>>> import test>>> test.__name__'test'